Inhaltsverzeichnis
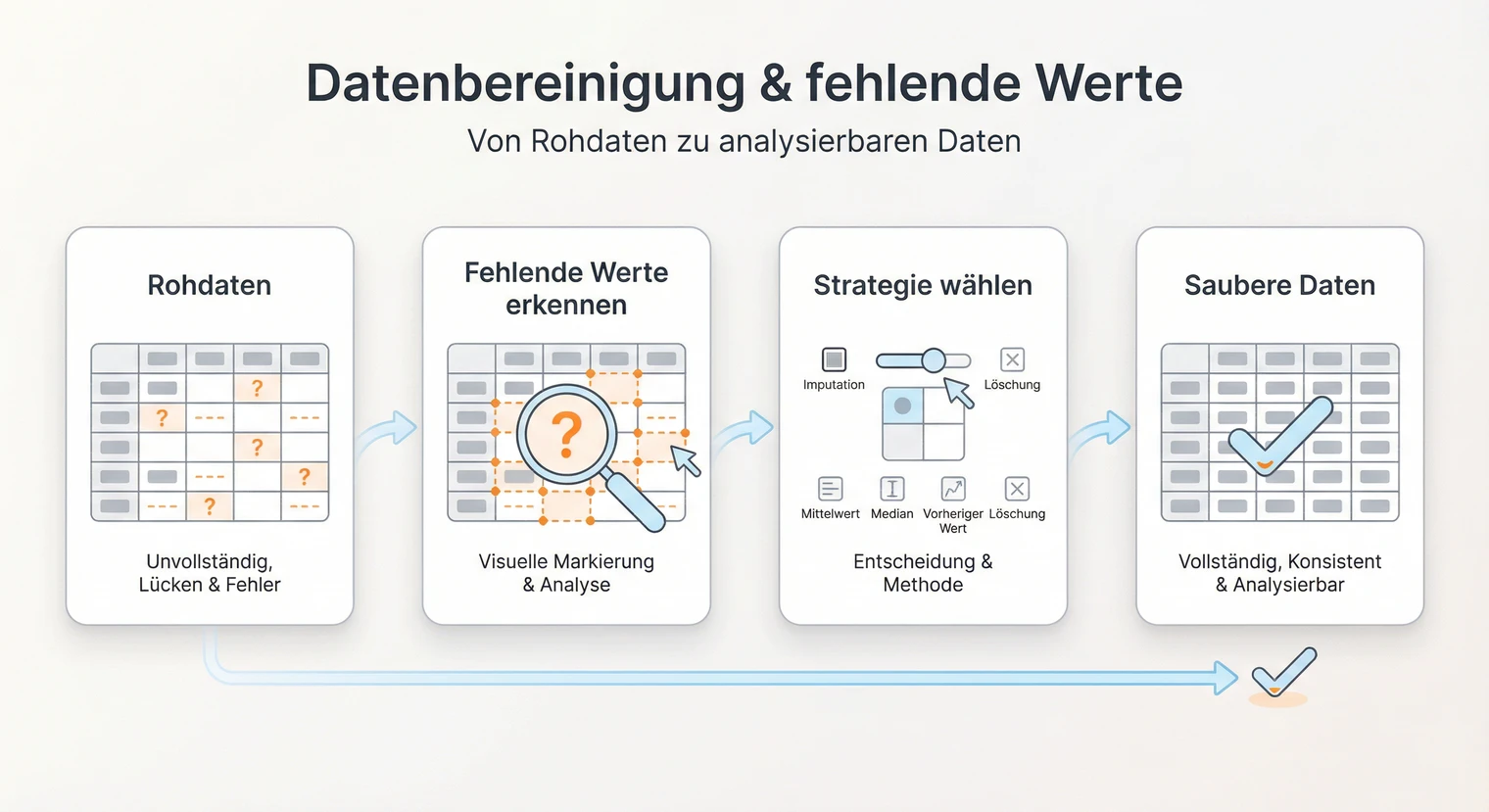
Die Datenbereinigung ist der erste und oft unterschätzte Schritt deiner Datenanalyse. Fehlende Werte, Ausreißer und Eingabefehler können deine Ergebnisse verzerren oder im schlimmsten Fall unbrauchbar machen. Hier erfährst du, wie du fehlende Werte systematisch erkennst, die passende Behandlungsstrategie wählst und alles nachvollziehbar dokumentierst.
Prüfe zuerst den Anteil und das Muster deiner fehlenden Werte. Bei wenigen zufälligen fehlenden Werten und geringem Fallverlust kann eine Complete-Case-Analyse vertretbar sein. Wenn das Fehlen mit beobachteten Variablen zusammenhängt, kommen ein passend spezifiziertes Imputations- oder Maximum-Likelihood-Modell infrage. Dokumentiere Annahmen, Diagnostik und Entscheidungen im Methodenteil.
Was zählt als fehlender Wert?
Nicht jede Lücke im Datensatz ist ein fehlender Wert im statistischen Sinn. Bevor du mit der Bereinigung startest, musst du unterscheiden, ob Daten tatsächlich fehlen oder ob die Lücke gewollt ist.
Strukturelle Lücken (Design-Missings): Entstehen durch Filterfragen oder logische Abhängigkeiten. Beispiel: „Wie viele Stunden arbeiten Sie pro Woche?" wird nur Erwerbstätigen gestellt. Nicht-Erwerbstätige haben hier keinen fehlenden Wert, sondern die Frage trifft schlicht nicht zu. Diese Fälle werden nicht imputiert, sondern als eigene Kategorie („nicht zutreffend") oder durch Stichprobenteilung behandelt.
Echte fehlende Werte: Die Frage war relevant, wurde aber nicht beantwortet. Beispiel: Eine erwerbstätige Person überspringt die Frage nach den Arbeitsstunden. Hier liegt ein fehlender Wert vor, der behandelt werden muss.
„Weiß nicht" und „Keine Angabe": Diese Antwortoptionen sind ein Sonderfall. Bei Wissens- oder Faktenfragen (z. B. „Wie hoch ist Ihr Nettoeinkommen?") ist „Weiß nicht" oft ein echter fehlender Wert und sollte als solcher behandelt werden. Bei Einstellungsfragen (z. B. „Wie zufrieden sind Sie mit...?") kann „Weiß nicht" dagegen eine inhaltlich relevante Kategorie sein. Prüfe die Fragelogik und entscheide begründet, ob du diese Fälle als fehlende Werte oder als eigene Ausprägung behandelst.
Fehlende-Werte-Codes prüfen: Viele Datensätze nutzen Platzhalter wie 99, -1, -9 oder leere Strings für fehlende Werte. Diese müssen vor der Analyse in das Missing-Format deiner Software umkodiert werden (NA in R, Systemfehlend in SPSS). Sonst werden sie als gültige Werte mitgerechnet und verfälschen deine Ergebnisse.
Workflow: Datenbereinigung in 7 Schritten
Ein systematischer Ablauf hilft dir, nichts zu übersehen und deine Entscheidungen nachvollziehbar zu dokumentieren.
1 Codes identifizieren und umkodieren: Prüfe, ob 99, -1, -9, leere Strings oder andere Platzhalter als fehlende Werte gemeint sind. Kodiere sie in NA (R) bzw. Systemfehlend (SPSS) um.
2 Anteil quantifizieren: Berechne den Anteil fehlender Werte pro Variable und pro Fall. Erstelle eine Übersicht (Tabelle oder Heatmap).
3 Muster visualisieren: Nutze Missing-Pattern-Plots (z. B. naniar::vis_miss() in R oder Missing Value Patterns in SPSS). Erkenne, ob bestimmte Variablen oder Fallgruppen betroffen sind.
4 Muster untersuchen: Nutze Musterplots, fachliches Wissen und passende Vergleiche. Der Little's MCAR-Test kann ergänzen, MCAR aber weder beweisen noch MAR von MNAR unterscheiden.
5 Strategie wählen: Entscheide anhand von Anteil, Muster und Skalenniveau (siehe Entscheidungsmatrix unten).
6 Robustheit prüfen: Wenn plausible Missing-Strategien zu unterschiedlichen Ergebnissen führen könnten, vergleiche gezielt geeignete Varianten und erkläre Abweichungen.
7 Dokumentieren: Halte im Methodenteil fest: n vor/nach Bereinigung, gewählte Strategie mit Begründung, bei Imputation m und verwendetes Modell, Ergebnis der Sensitivitätsanalyse.
Fehlende Werte klassifizieren: MCAR, MAR, MNAR
Die Wahl der Behandlungsstrategie hängt davon ab, warum Daten fehlen. Die Statistik unterscheidet drei Muster, die unterschiedliche Konsequenzen für deine Analyse haben.
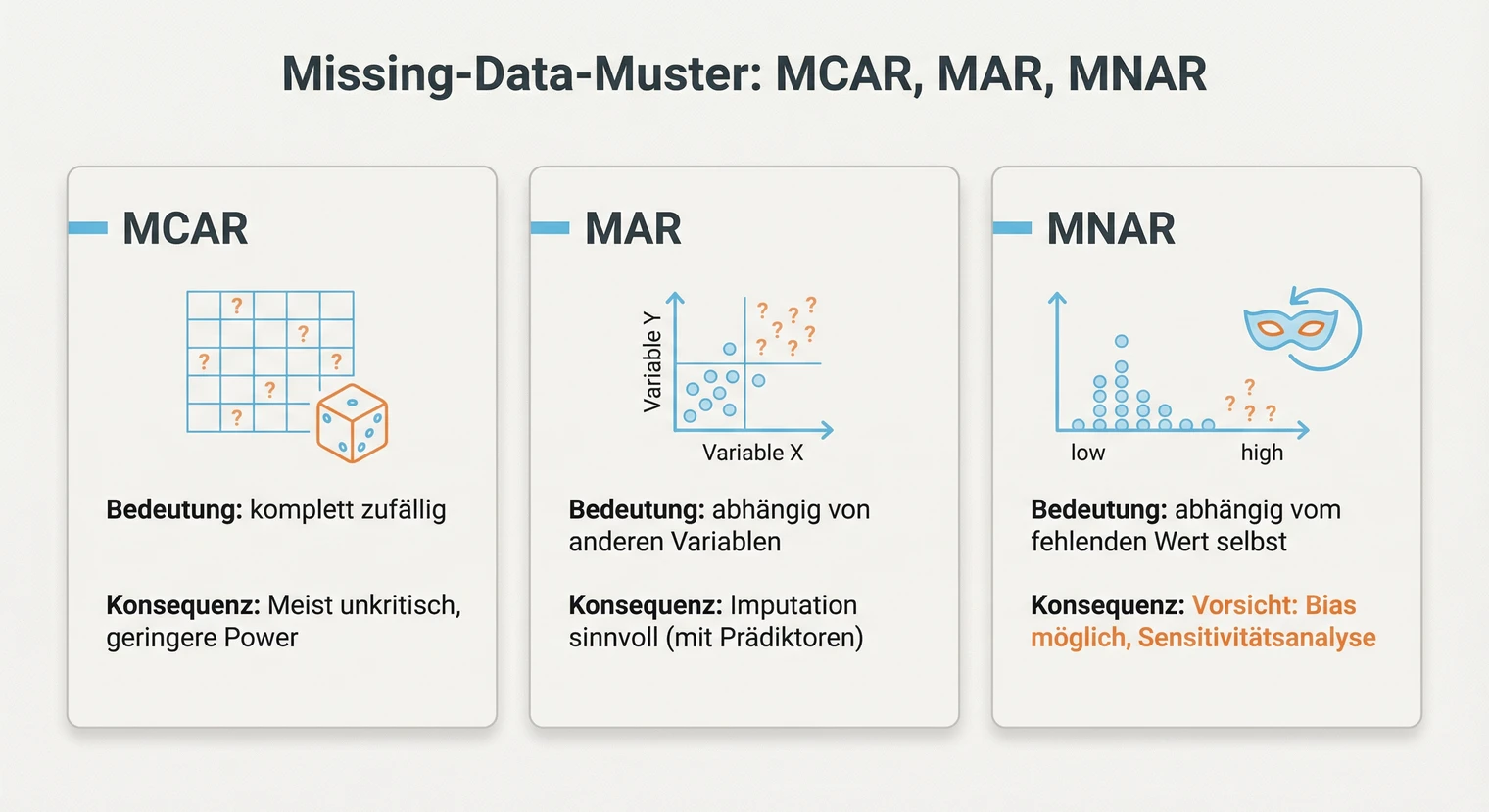
MCAR (Missing Completely At Random): Das Fehlen ist komplett zufällig und hängt weder von der fehlenden Variable selbst noch von anderen Variablen ab. Beispiel: Ein Teilnehmer überspringt versehentlich eine Frage, weil er zu schnell weiterklickt. Bei MCAR sind die verbleibenden Daten repräsentativ. Listwise deletion führt zu Stichprobenverkleinerung, aber nicht zu Verzerrung.
MAR (Missing At Random): Das Fehlen hängt von anderen beobachteten Variablen ab, nicht aber vom fehlenden Wert selbst. Beispiel: Jüngere Befragte beantworten eine Frage zum Einkommen seltener als Ältere. Das Fehlen korreliert mit Alter, nicht mit dem Einkommen selbst. Moderne Verfahren wie multiple Imputation oder FIML können unter MAR und bei passend spezifiziertem Modell die beobachteten Zusammenhänge für weniger verzerrte Schätzungen nutzen.
MNAR (Missing Not At Random): Das Fehlen hängt vom fehlenden Wert selbst ab. Beispiel: Personen mit sehr hohem Einkommen verweigern häufiger die Angabe ihres Einkommens. Standardverfahren (listwise, Imputation, FIML) können bei MNAR zu verzerrten Ergebnissen führen. Du brauchst theoretische Argumente und ggf. Sensitivitätsanalysen. Im Diskussionsteil solltest du MNAR-Risiken als Limitation benennen.
In der Praxis lässt sich MCAR mit dem Little's MCAR-Test prüfen. Ein nicht signifikanter Test beweist MCAR allerdings nicht – er macht es nur plausibel (bei kleinen Stichproben hat der Test wenig Power). Kombiniere den Test daher mit Musterplots und Gruppenvergleichen. Die Unterscheidung zwischen MAR und MNAR ist rein statistisch nicht möglich. Hier brauchst du inhaltliche Überlegungen: Warum könnten die Daten fehlen? Sensitivitätsanalysen sind hier der zentrale Robustheitscheck, wenn MNAR fachlich plausibel ist. Dokumentiere deine Einschätzung und begründe, warum du MAR gegebenenfalls für plausibel hältst.
Strategien für den Umgang mit fehlenden Werten
Die richtige Strategie hängt von Anteil, Muster und Skalenniveau ab. Die folgende Matrix hilft dir bei der Entscheidung.
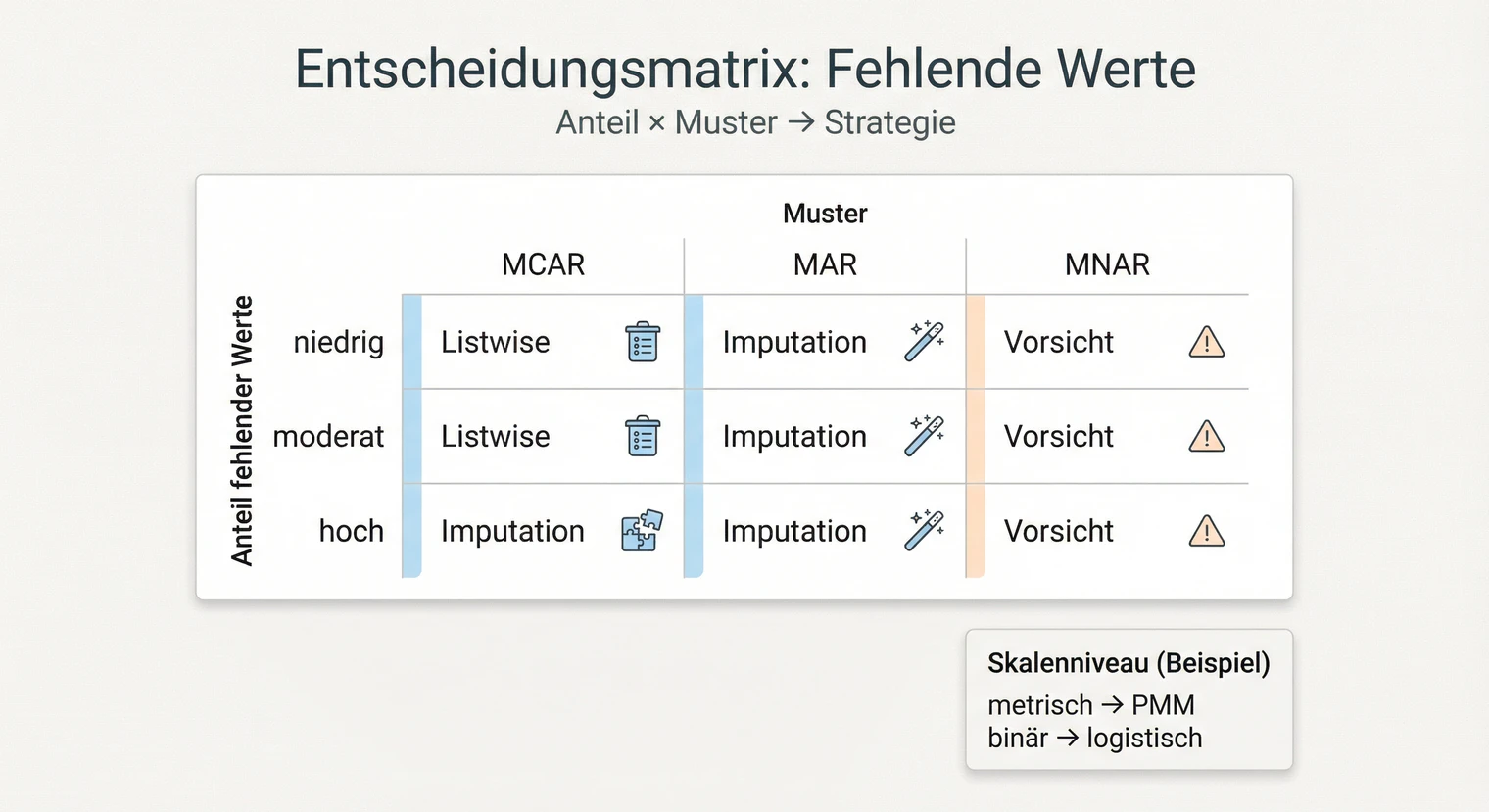
Wenig Fallverlust + MCAR plausibel
Eine Complete-Case-Analyse kann vertretbar sein, wenn ihre Annahmen zum Analysemodell passen und Präzision sowie Zusammensetzung der Stichprobe erhalten bleiben. Prüfe das resultierende n und vergleiche ein- und ausgeschlossene Fälle.
Relevanter Informationsverlust + MAR plausibel
Multiple Imputation oder FIML können verfügbare Informationen nutzen. Voraussetzung sind ein zum Datentyp und zur späteren Analyse passendes Modell sowie plausible MAR-Annahmen.
MNAR plausibel oder zentrale Variable stark betroffen
Vorsicht: Auch Imputation kann verzerrt sein. Prüfe zuerst: Sensitivitätsanalyse mit verschiedenen Strategien, alternative Modellspezifikation, Fragelogik und Skalierung überdenken. Variablenausschluss ist der letzte Ausweg, nicht die erste Lösung. Bedenke: Ein Ausschluss verändert die Forschungsfrage und muss inhaltlich begründet werden. MNAR-Risiko immer als Limitation benennen.
Skalenniveau beachten
Metrisch: PMM (Predictive Mean Matching) oder Regression. Binär: Logistische Imputation. Ordinal: Proportional Odds oder ordinale logistische Modelle.
Wichtig: Die Prozentangaben sind Richtwerte, keine festen Grenzen. Welche Strategie angemessen ist, hängt auch vom Fach, Modell und der Betreuung ab. Besprich deine Entscheidung im Zweifel vorab. Nicht empfohlen: Mittelwert-Ersetzung, pairwise deletion, single Imputation ohne Unsicherheitsberücksichtigung.
Sensitivitätsanalysen sind besonders wichtig, wenn mehrere vertretbare Annahmen oder Missing-Strategien zu anderen Schlussfolgerungen führen könnten. Vergleiche dann gezielt passende Ansätze, statt routinemäßig beliebige Verfahren gegenüberzustellen. Bleiben die Aussagen stabil, spricht das für Robustheit; ändern sie sich, berichte und erkläre die Unterschiede.
Multiple Imputation: Modelle und Diagnostik
Multiple Imputation (MI) ersetzt jeden fehlenden Wert mehrfach auf Basis der vorhandenen Daten. Die Analysen werden auf allen imputierten Datensätzen durchgeführt und die Ergebnisse nach Rubin's Rules kombiniert. Der Vorteil: Die Unsicherheit der Schätzung wird berücksichtigt.
PMM (Predictive Mean Matching): Eine häufige Option für metrische Variablen. Es zieht beobachtete Werte aus Fällen mit ähnlichen Vorhersagen und kann dadurch plausible Wertebereiche besser erhalten als eine einfache lineare Ersetzung. Ob PMM zum Analysemodell passt, musst du dennoch prüfen.
Logistische Imputation: Für binäre Variablen (0/1, ja/nein). Schätzt die Wahrscheinlichkeit und zieht daraus den imputierten Wert.
Proportional Odds / ordinale logistische Modelle: Für ordinale Variablen (Likert-Skalen als Einzelitems). Berücksichtigt die Rangfolge der Kategorien.
Tipp: In R setzt das mice-Paket Ausgangsmethoden anhand des Variablentyps. Prüfe diese zusammen mit Prädiktoren, Wertebereichen und deinem späteren Analysemodell.
FIML oder Multiple Imputation? FIML (Full Information Maximum Likelihood) ist eine Alternative zu MI und besonders geeignet, wenn dein Hauptmodell ohnehin mit Maximum Likelihood geschätzt wird (z. B. Strukturgleichungsmodelle in lavaan oder Mplus). FIML schätzt Parameter und Missing-Handling in einem Schritt und erfordert keine separaten imputierten Datensätze. MI ist flexibler, wenn du verschiedene Analyseverfahren nutzt oder die Daten vor der Analyse explorativ erkunden willst. Beide Verfahren können unter plausibler MAR-Annahme und bei richtig spezifiziertem Modell konsistente Schätzungen liefern. Einschränkung: Je nach Software kann FIML bei fehlenden Werten in exogenen Variablen (unabhängige Variablen ohne Residuum im Modell) Probleme bereiten. Prüfe die Dokumentation deines Tools; im Zweifel MI oder eine Modellanpassung (z. B. exogene als endogene Variable modellieren).
Wie viele Imputationen (m)? Wähle m anhand des Informationsverlusts und der benötigten Genauigkeit. Starte für eine einfache Übungsanalyse beispielsweise mit m = 20 und prüfe, ob Schätzungen, Standardfehler und Monte-Carlo-Unsicherheit bei mehr Imputationen stabil bleiben. Mehr Imputationen reduzieren die zusätzliche Simulationsunsicherheit, ersetzen aber kein gutes Imputationsmodell. Dokumentiere die gewählte Zahl und deine Diagnose.
Verteilungen vergleichen: Plotte beobachtete vs. imputierte Werte. Die Verteilungen müssen unter MAR nicht identisch sein. Unerwartete Abweichungen sollten sich aber durch das Modell und die beobachteten Zusammenhänge erklären lassen.
Konvergenz prüfen: Bei MICE sollte die Konvergenz der Kettenplots (trace plots) geprüft werden. Achte auf durchmischte Ketten ohne systematischen Drift statt auf ein einzelnes formales Gütesiegel.
Plausibilität: Liegen die imputierten Werte im sinnvollen Bereich? Ein imputiertes Alter von 150 Jahren deutet auf ein Problem hin.
Imputationsmodell passend aufbauen: Es sollte mit deinem Analysemodell vereinbar sein und relevante Ziel-, Prädiktor- sowie Hilfsvariablen enthalten, die Werte oder Missingness erklären. Interaktionen, Transformationen und die Datenstruktur müssen gegebenenfalls ebenfalls abgebildet werden.
Design-Missings nicht imputieren: Stelle sicher, dass strukturelle Lücken (Filterfragen, „nicht zutreffend") nicht imputiert werden. In mice steuerst du das über eine where-Matrix:
# where-Matrix: TRUE = imputieren, FALSE = nicht imputieren
where_matrix <- is.na(daten)
# Design-Missings ausschließen (z. B. Arbeitsstunden für Nicht-Erwerbstätige)
where_matrix[daten$erwerbstaetig == 0, "arbeitsstunden"] <- FALSE
imp <- mice(daten, m = 20, where = where_matrix)
Ohne diese Maske erzeugt mice künstliche Werte, wo gar keine fehlen – das verfälscht deine Daten.
Ausreißer identifizieren und behandeln
Neben fehlenden Werten gehören Ausreißer zur Datenbereinigung. Ein Ausreißer ist ein Wert, der ungewöhnlich weit vom Rest der Verteilung entfernt liegt. Das kann ein Eingabefehler sein, aber auch ein echter Extremfall.
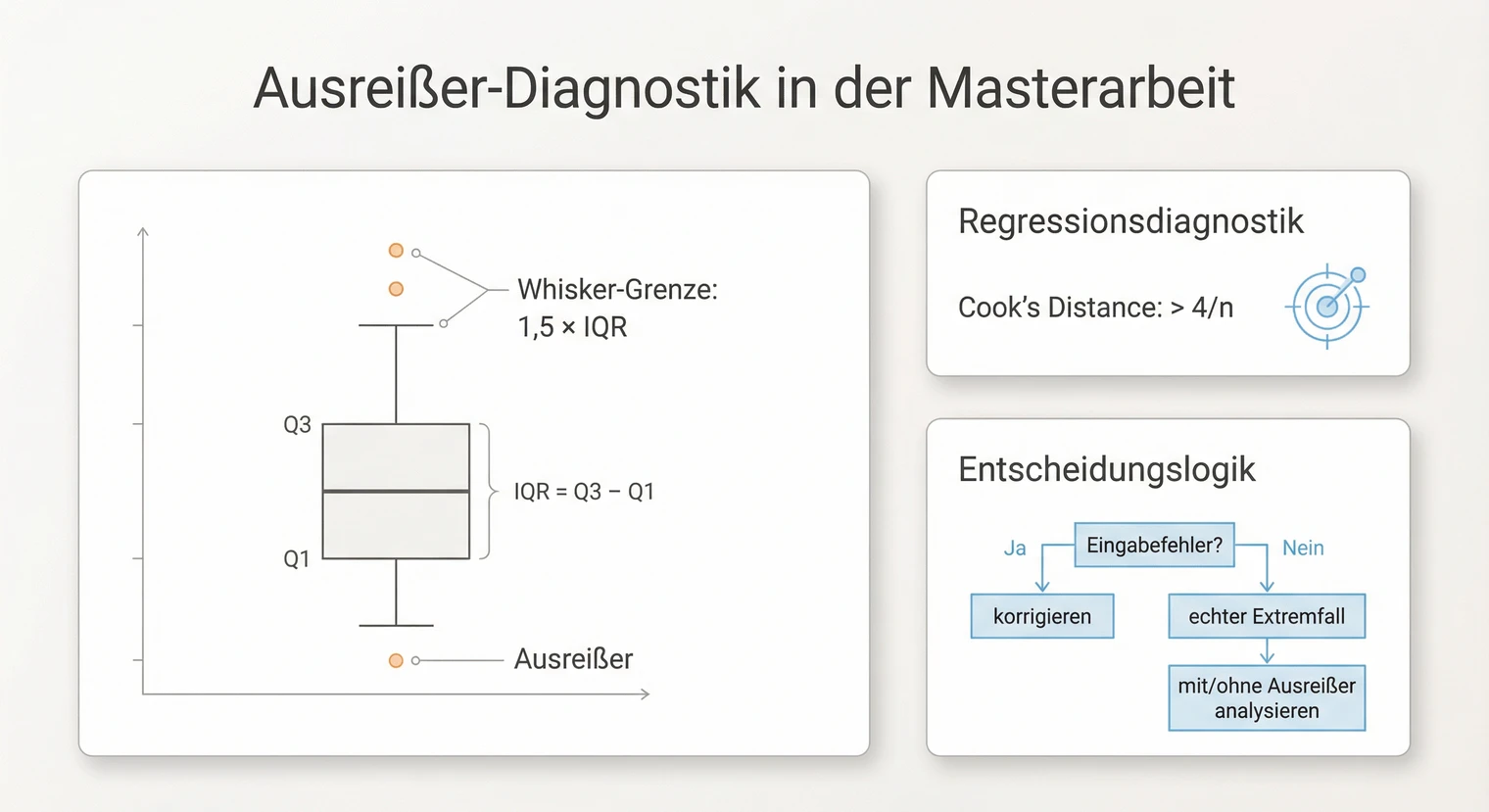
Identifikation: Boxplots zeigen Werte außerhalb der Whisker (1,5-facher Interquartilsabstand) als potenzielle Ausreißer. Bei Regressionen liefern Cook's Distance und standardisierte Residuen zusätzliche Hinweise. Gängige Richtwerte sind Cook's D > 4/n und Residuen > |3|. Nutze diese Schwellen als Startpunkt, danach immer inhaltlich prüfen und dokumentieren. Ob ein Wert problematisch ist, hängt vom Kontext ab: Ein Alter von 150 Jahren ist offensichtlich ein Fehler, ein Alter von 85 Jahren kann dagegen ein valider Extremfall sein.
Behandlung: Automatisches Löschen von Ausreißern ist keine gute Strategie. Prüfe zunächst, ob ein Eingabefehler vorliegt. Wenn ja, korrigiere den Wert oder setze ihn auf fehlend. Bei echten Extremfällen führst du die Analyse mit und ohne den Ausreißer durch. Wenn die Ergebnisse stabil bleiben, behältst du den Wert. Wenn nicht, dokumentiere beide Varianten und begründe deine finale Entscheidung.
Software-Tools: SPSS und R konkret
Hier findest du konkrete Anleitungen für die gängigsten Tools. Kopiere die Menüpfade bzw. den Code und passe ihn an deine Daten an.
Fehlende Werte definieren: Variablenansicht → Spalte „Fehlend" → Werte wie 99, -1 als fehlend markieren.
Missing-Analyse: Analysieren → Fehlende Werte → Variablen auswählen → „EM" aktivieren → OK. Little's MCAR-Test erscheint in der EM-Ausgabe. Die Funktion setzt je nach Lizenz die SPSS-Option „Missing Values" voraus.
Multiple Imputation: Analysieren → Multiple Imputation → Fehlende Werte imputieren → Variablen und m festlegen → unter „Methode" automatische oder begründet angepasste Modelle wählen → Ausgabe-Datensatz benennen.
Ausreißer: Analysieren → Deskriptive Statistiken → Explorative Datenanalyse → Diagramme → Boxplots aktivieren.
Für den Methodenteil: Exportiere die EM-Ausgabe und den MCAR-Test (χ², df, p). Bei Imputation: Nenne m und die Methode.
Missing-Pattern visualisieren:
library(naniar)
vis_miss(daten) # Heatmap fehlender Werte
gg_miss_var(daten) # Anteil pro Variable
Little's MCAR-Test:
library(naniar)
mcar_test(daten) # gibt chi², df, p aus
Wichtig zur Interpretation: Ein nicht signifikanter Test beweist MCAR nicht – er macht es nur plausibel. Bei kleinen Stichproben hat der Test wenig Power. Ergänze ihn durch Musterplots, fachliche Argumente und geeignete Vergleiche. Die Funktion ist in der CRAN-Dokumentation von naniar beschrieben.
Multiple Imputation mit mice:
library(mice)
ini <- mice(daten, maxit = 0, printFlag = FALSE)
method <- ini$method # prüfen und fachlich anpassen
imp <- mice(daten, m = 20, method = method, seed = 2026)
fit <- with(imp, lm(y ~ x1 + x2))
pool(fit) # Ergebnisse kombinieren
Wichtig: mice wählt automatisch passende
Ausgangsmethoden nach dem in R hinterlegten Variablentyp. Prüfe method, Prädiktormatrix, Wertebereiche und Modellstruktur vor der eigentlichen Imputation. Die aktuelle
mice-Dokumentation beschreibt die Standardmethoden und Optionen.
Dokumentation und Reporting
Eine saubere Dokumentation macht deine Datenbereinigung nachvollziehbar. Im Methodenteil beschreibst du das Vorgehen, im Ergebnisteil berichtest du Sensitivitätsanalysen, in der Diskussion benennst du Limitationen.
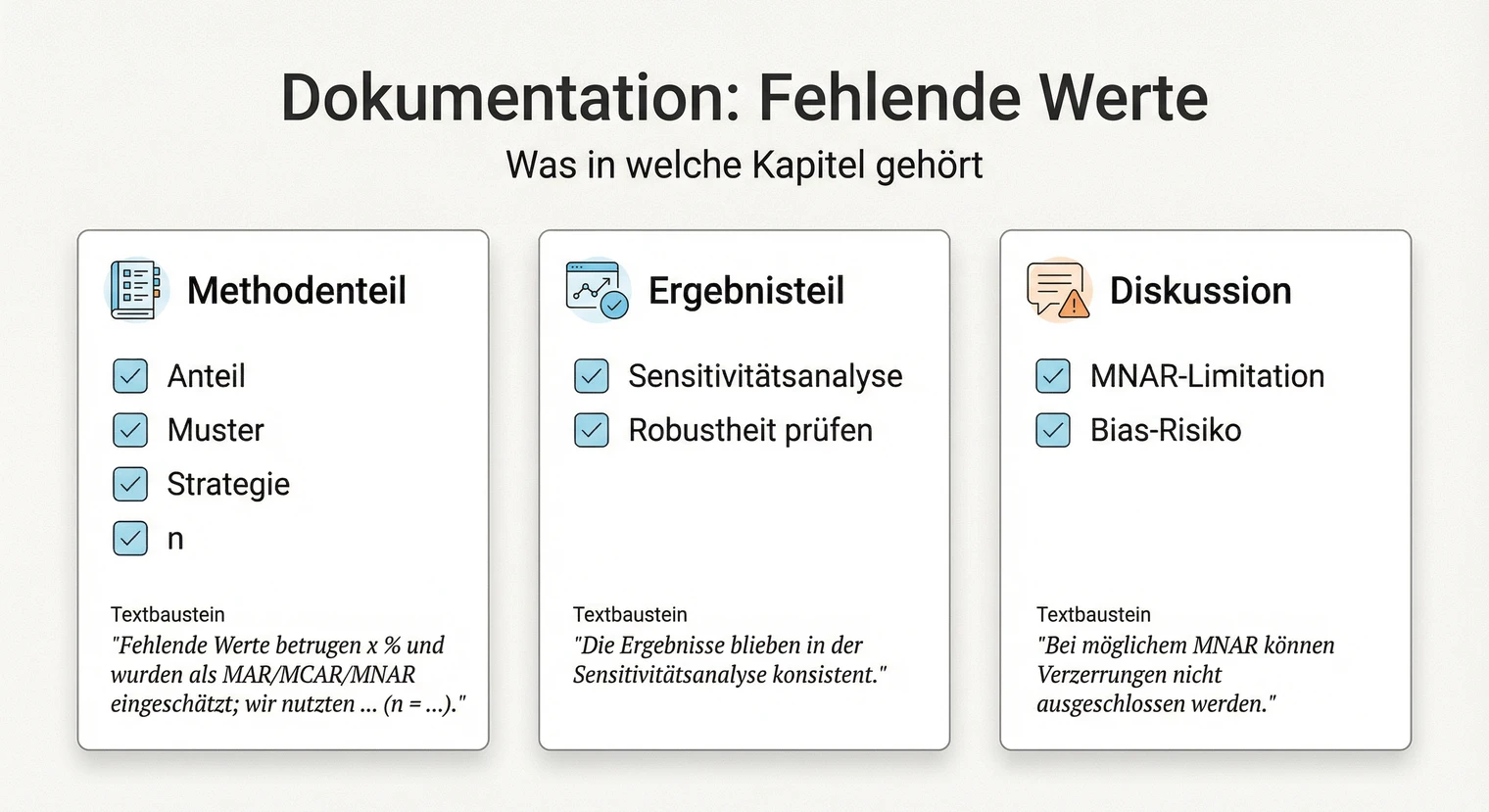
Methodenteil (listwise deletion)
„Vor der Analyse wurden die Rohdaten auf Vollständigkeit geprüft. Der Anteil fehlender Werte lag zwischen [Min] % und [Max] % (M = [Mittelwert] %). Der Little's MCAR-Test war nicht signifikant, χ²([df]) = [Wert], p = [p-Wert]. In Kombination mit den Musterplots und Gruppenvergleichen wurde MCAR als plausibel eingeschätzt. Aufgrund des geringen Anteils wurden Fälle mit fehlenden Werten bei zentralen Variablen ausgeschlossen (listwise deletion). Die finale Stichprobe umfasst n = [Stichprobengröße]."
Methodenteil (mit Imputation)
„Fehlende Werte (M = [Anteil] %) wurden mittels multipler Imputation behandelt (mice-Paket in R, m = [Anzahl], PMM für metrische, logistische Imputation für binäre Variablen). Der Little's MCAR-Test war signifikant, χ²([df]) = [Wert], p = [p-Wert]. Gruppenvergleiche zeigten, dass [Gruppe] häufiger Angaben zu [Variable] verweigerte. MAR wurde daher als plausibel angenommen."
Ergebnisteil (Sensitivitätsanalyse)
„Zur Prüfung der Robustheit wurde die Hauptanalyse zusätzlich mit listwise deletion durchgeführt. Die Ergebnisse waren konsistent: Der Effekt von [UV] auf [AV] blieb signifikant (MI: β = [Wert], p = [p]; listwise: β = [Wert], p = [p]). Die Schlussfolgerungen bleiben von der Wahl der Missing-Strategie unberührt." (Alternativ bei divergenten Ergebnissen: beide berichten und diskutieren.)
Diskussion (MNAR-Limitation)
„Eine Einschränkung betrifft die fehlenden [Variable]-Angaben. Obwohl MAR auf Basis der beobachteten Zusammenhänge plausibel erscheint, kann MNAR nicht ausgeschlossen werden: [Beschreibung des möglichen systematischen Ausfalls]. In diesem Fall wären auch die imputierten Werte verzerrt. Die Sensitivitätsanalyse zeigte jedoch [robuste/abweichende] Ergebnisse."
Missing-Codes nicht umkodieren: Werte wie 99 oder -1 werden als gültige Daten mitberechnet. → Vor jeder Analyse alle Codes in NA/Systemfehlend umwandeln.
Muster nicht prüfen: Listwise deletion bei MAR/MNAR verzerrt die Stichprobe. → Missing-Pattern, Fallverlust und plausible Ursachen untersuchen; ein einzelner Test reicht nicht.
Design-Missings imputieren: Filterfragen-Lücken sind keine echten fehlenden Werte. → Strukturelle Lücken separat behandeln, nicht imputieren.
Keine Sensitivitätsanalyse: Eine einzige Strategie lässt Unsicherheit offen, wenn mehrere Annahmen plausibel sind. → Dann gezielt passende Varianten vergleichen und berichten.
Nächste Schritte
Wenn deine Daten bereinigt sind, folgt die eigentliche Analyse. Mit sauberen Daten kannst du dich auf die inhaltlichen Fragen konzentrieren, statt dich mit technischen Problemen herumzuschlagen.
Der nächste Schritt ist die Datenanalyse. Dort wählst du das passende Verfahren für deine Forschungsfrage, prüfst die Voraussetzungen und führst die inferenzstatistischen Tests durch.
Falls du mit Statistik noch unsicher bist, hilft dir der entsprechende Ratgeber bei der Auswahl des richtigen Verfahrens. Für die Darstellung der Ergebnisse findest du dort Formulierungsbausteine und Reporting-Checklisten.
Wenn deine Arbeit inhaltlich fertig ist und du sie drucken und binden lassen möchtest, kannst du das bei BachelorHero online konfigurieren.
Häufig gestellte Fragen
Ab welchem Anteil fehlender Werte wird es problematisch?
Eine feste Grenze gibt es nicht. Entscheidend sind neben dem Anteil das Muster, die betroffenen Variablen, der Fallverlust und dein Analysemodell. Systematische fehlende Werte können schon bei einem kleinen Anteil problematisch sein; ein größerer Anteil kann mit einem passenden Modell dennoch analysierbar sein. Begründe die Strategie und prüfe, wie empfindlich die Ergebnisse darauf reagieren.
Wie erkenne ich, ob meine fehlenden Werte zufällig sind?
Nutze Musterplots, fachliches Wissen und geeignete Vergleiche. Der Little's MCAR-Test (SPSS: Analysieren → Fehlende Werte; R: naniar::mcar_test()) kann ergänzen. Ist er nicht signifikant, macht das MCAR allenfalls plausibel – beweisen kann er es nicht. MAR und MNAR sind aus den beobachteten Daten nicht sicher trennbar; dafür brauchst du inhaltliche Argumente und gegebenenfalls Sensitivitätsanalysen.
Was mache ich mit Codes wie 99 oder -1 im Datensatz?
Viele Datensätze nutzen Platzhalter wie 99, -1, -9 oder leere Strings für fehlende Werte. Bevor du analysierst, musst du diese in das Missing-Format deiner Software umkodieren: NA in R, Systemfehlend in SPSS. Sonst werden sie als gültige Werte mitgerechnet. Prüfe im Codebuch oder der Dokumentation, welche Codes verwendet wurden.
Wann ist „Weiß nicht" ein fehlender Wert, wann eine eigene Kategorie?
Das hängt von der Fragelogik ab. Bei Faktenfragen (z. B. Einkommen, Alter) ist „Weiß nicht" meist ein echter fehlender Wert. Bei Einstellungsfragen (z. B. Zufriedenheit) kann es eine inhaltlich relevante Antwort sein, etwa wenn echte Ambivalenz vorliegt. Entscheide begründet und dokumentiere deine Entscheidung im Methodenteil.
Wie gehe ich mit Filterfragen und Design-Missings um?
Strukturelle Lücken durch Filterfragen (z. B. Arbeitsstunden nur für Erwerbstätige) sind keine echten fehlenden Werte. Imputiere sie nicht. Kodiere „nicht zutreffend" getrennt und definiere für die jeweilige Analyse die passende Teilstichprobe. Bei Imputation muss eine Maske verhindern, dass solche Felder Werte erhalten (z. B. über where in mice).
Wie wähle ich die Anzahl der Imputationen (m)?
Es gibt keine für alle Datensätze passende Zahl. Wähle m so, dass Schätzungen und Standardfehler bei wiederholter Imputation hinreichend stabil sind; der Informationsverlust, das Modell und die gewünschte Genauigkeit spielen dabei eine Rolle. m = 20 kann ein Startwert für eine Übungsanalyse sein, muss aber diagnostisch geprüft und gegebenenfalls erhöht werden. Dokumentiere und begründe die Wahl.
Wie prüfe ich, ob die Imputation gut funktioniert hat?
Prüfe mindestens drei Ebenen: (1) Lassen sich Unterschiede zwischen beobachteten und imputierten Verteilungen durch das Modell erklären? (2) Zeigen MICE-Kettenplots durchmischte Ketten ohne systematischen Drift? (3) Sind die Werte inhaltlich plausibel? Ein imputiertes Alter von 150 Jahren deutet beispielsweise auf ein Problem hin.
Was ist der Unterschied zwischen listwise und pairwise deletion?
Listwise deletion entfernt alle Fälle mit mindestens einem fehlenden Wert. Die Stichprobe wird kleiner, aber alle Analysen basieren auf denselben Fällen. Pairwise deletion nutzt alle verfügbaren Daten pro Variablenpaar, führt aber zu unterschiedlichen Stichprobengrößen je Analyse. Pairwise deletion kann zu inkonsistenten Ergebnissen führen und wird meist nicht empfohlen.
 Qualitative Inhaltsanalyse
Qualitative Inhaltsanalyse  Seitenzahlen richtig einfügen
Seitenzahlen richtig einfügen  Wissenschaftlicher Schreibstil
Wissenschaftlicher Schreibstil